Shine a Light - ein Hybrides Cluster zum Anfassen
Kubernetes Cluster sind in der Regel nicht sehr anschaulich. Man klickt sich beim Cloudprovider seiner Wahl durch und sieht seine Pods und Nodes lediglich in Text Form. Deswegen haben wir ein Cluster gebaut, wo es richtig was zu sehen gibt.
\

\
Peter hat schon vor einiger Zeit auf Basis von diesem Repository eine Demo für ein Kubernetes Cluster mit Raspberry Pi’s gebaut. Die Demo war allerdings beschränkt auf Raspberry Pis und das Pimoroni Blinkt Device.
Mit unserer neuen Version ist dies nicht mehr der Fall. Nun kann man verschiedenste Prozessorarchitekturen und Devices benutzen. Außerdem läuft die Demo jetzt auf Kubernetes 1.13.4 und Docker 18.09 .
Funktion
Damit auf allen Nodes die markierten Pods angezeigt werden, wird unsere Controller-App als DaemonSet deployed.
Je nach Rolle der Nodes wird ein Daemonset mit dem entspechenden Agent deployed, für die Standard Pimoroni Blinkts wäre die richtige Rolle blinkt.
\
Um später verschiedene Devices zu unterstützen, haben wir die Kommunikation mit der Kubernetes API und der Steuerung der LED’s entkoppelt.
Der Controller empfängt die Informationen von der API, ob ein neuer Pod auf diesem Node gescheduled oder gelöscht wurde und gibt diese Information per JSON HTTP Anfrage an den Agent weiter, der sich darum kümmert, die entsprechende Anzahl an LED’s auf seinem spezifischen Gerät zum Leuchten zu bringen.
Damit ein Pod angezeigt wird, müssen entsprechende Labels gesetzt sein:
spec:
template:
metadata:
labels:
blinkt: show
blinktColor: ffff00
Aufbau

\
Der Kern der App ist der Controller. Dieser bekommt alle seine Informationen von der k8s-API. Wenn der Controller eine Mitteilung darüber bekommt, dass ein Pod auf seiner Node hinzugefügt oder entfernt wurde, sendet er diese Information via HTTP an den Agent.
Controller und Agent laufen in einem Pod und können daher einfach über localhost kommunizieren.
Controller
\

Das Herz des Controllers sind zwei Funktionen, die ihre Informationen von der K8s-API bekommen.
func (b *Impl) StartWatchingPods() {
log.Println("Starting new K8sController")
b.podStore, b.podController = cache.NewInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
return b.clientset.CoreV1().Pods(b.PodConfig.Namespace).List(b.listOptions)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
return b.clientset.CoreV1().Pods(b.PodConfig.Namespace).Watch(b.listOptions)
},
},
&v1.Pod{},
b.resyncPeriod,
b.newResourceEventHandlerFuncs(),
)
go b.podController.Run(b.stopCh)
s<-b.stopCh
log.Println("Shutting down K8sController")
}
Die StartWatchingPods() Funktion hört auf die k8s-API und filtert alle Änderungen heraus, die mit dem gegebenen Namespace verbunden sind. Wenn sich etwas im Namespace ändert (Pods werden hinzugefügt/entfernt), werden die Daten an die newResourceEventHandlerFuncs() Funktion weitergeleitet.
func (b *Impl) newResourceEventHandlerFuncs() cache.ResourceEventHandlerFuncs{
return cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
b.addPod(obj.(*v1.Pod))
},
UpdateFunc: func(old, new interface{}) {},
DeleteFunc: func(obj interface{}) {
b.removePod(obj.(*v1.Pod))
},
}
}
Hier werden die Änderungen weiter gefiltert.
- Wenn ein Pod hinzugefügt wurde, dann wird die
add.Pod()Funktion aufgerufen, wo Name und Farbe des Pods an den Agent gesendet werden - Wenn ein Pod entfernt wurde, dann wird die
remove.Pod()Funktion aufgerufen, wo Name und Farbe des Pods an den Agent gesendet werden - Updates, die uns die API mitteilt, verwerfen wir momentan.
Agent
Die einzige Vorraussetung für den Agent ist, dass er eine HTTP Schnittstelle anbietet und mit den Informationen aus dem übermittelten JSON die Anzahl an Pods auf dem Knoten anzeigt. Er ist außerdem für den State verantwortlich.
Die Daten, die der Controller übermittelt, haben folgende Form:
{
"action":"xxx", // hizugefügt/entfernt
"pod":"xxx", // Name des Pods
"color":"xxx" // Farbe des Pods
}
In unserem Fall kontrolliert der Agent eine Blinkt LED Leiste.
func main() {
log.Println("Started Receiver")
InitBlinkt()
router := mux.NewRouter()
router.HandleFunc("/data", handle).Methods("POST")
router.HandleFunc("/", get).Methods("GET")
log.Fatal(http.ListenAndServe(":5000", router))
log.Println("Started Listening")
}
Es gibt zwei HTTP Endpoints:
http://blinkt-rest:5000/gibt dem Controller einen HealthCheck, den er im Retrier benutzt, um zu prüfen, ob der Agent online ist.http://blinkt-rest:5000/dataist der Entpoint, wo die Informationen über die Pods ankommen.
Der Agent nutzt ein Slice aus pod structs als Datenstruktur, um die Pods zu speichern.
type pod struct {
name string
color string
}
\
Wenn ein Pod hinzugefügt wurde, wird die add Funktion aufgerufen, welche den Pod im Slice ablegt und mit seiner Farbe anzeigt.
func add(name string, color string) {
podList = append(podList, pod{name: name, color: color})
numPods := len(podList)
if color == "" {
color = blue
}
if numPods < 9 {
newPixel := numPods - 1
bl.SetPixelHex(newPixel, podList[newPixel].color)
bl.SetPixelBrightness(newPixel, defaultPixelBrightness)
bl.Show()
}
}
Wenn ein Pod entfernt wurde, wird im Slice nach dem Pod gesucht. Sollte er vorhanden sein, wird er aus dem Slice entfernt, die LED für den Pod blinkt rot und alle anderen Pods werden aufgerückt, damit keine Lücken in der LED Leiste entstehen.
func remove(name string, color string) {
ok, podIdx := false, 0
for i := range podList {
if name == podList[i].name {
ok = true
podIdx = i
break
}
}
if !ok {
log.Println("Error: pod not found in list")
return
}
if podIdx == len(podList)-1 {
podList = podList[:podIdx]
} else {
podList = append(podList[:podIdx], podList[podIdx+1:]...)
}
endIdx := len(podList)
log.Println("Pod removed: ", name, " Total Pods: ", endIdx)
if podIdx < 8 {
bl.FlashPixel(podIdx, 2, red)
if endIdx > 8 {
endIdx = 8
}
if endIdx < 8 {
for pixel := endIdx; pixel < 8; pixel++ {
bl.SetPixel(pixel, 0, 0, 0)
}
}
for pixel, pod := range podList[:endIdx] {
color := pod.color
if color == "" {
color = blue
}
bl.SetPixelHex(pixel, color)
bl.SetPixelBrightness(pixel, defaultPixelBrightness)
}
bl.Show()
}
}
Upgrade Strategies
Ein weiterer Aspekt, den wir gerne visualisieren wollten, waren Upgrades.
Wie läuft ein Bluegreen Deployment wirklich ab?
Was passiert bei einem Rolling Upgrade?
Damit es auch was zum selbst ausprobieren gibt, haben wir für die DevOps Gathering eine Web Frontend gebaut, was sowohl verschiedene Upgradestrategien als auch einfaches Scaling ermöglicht.
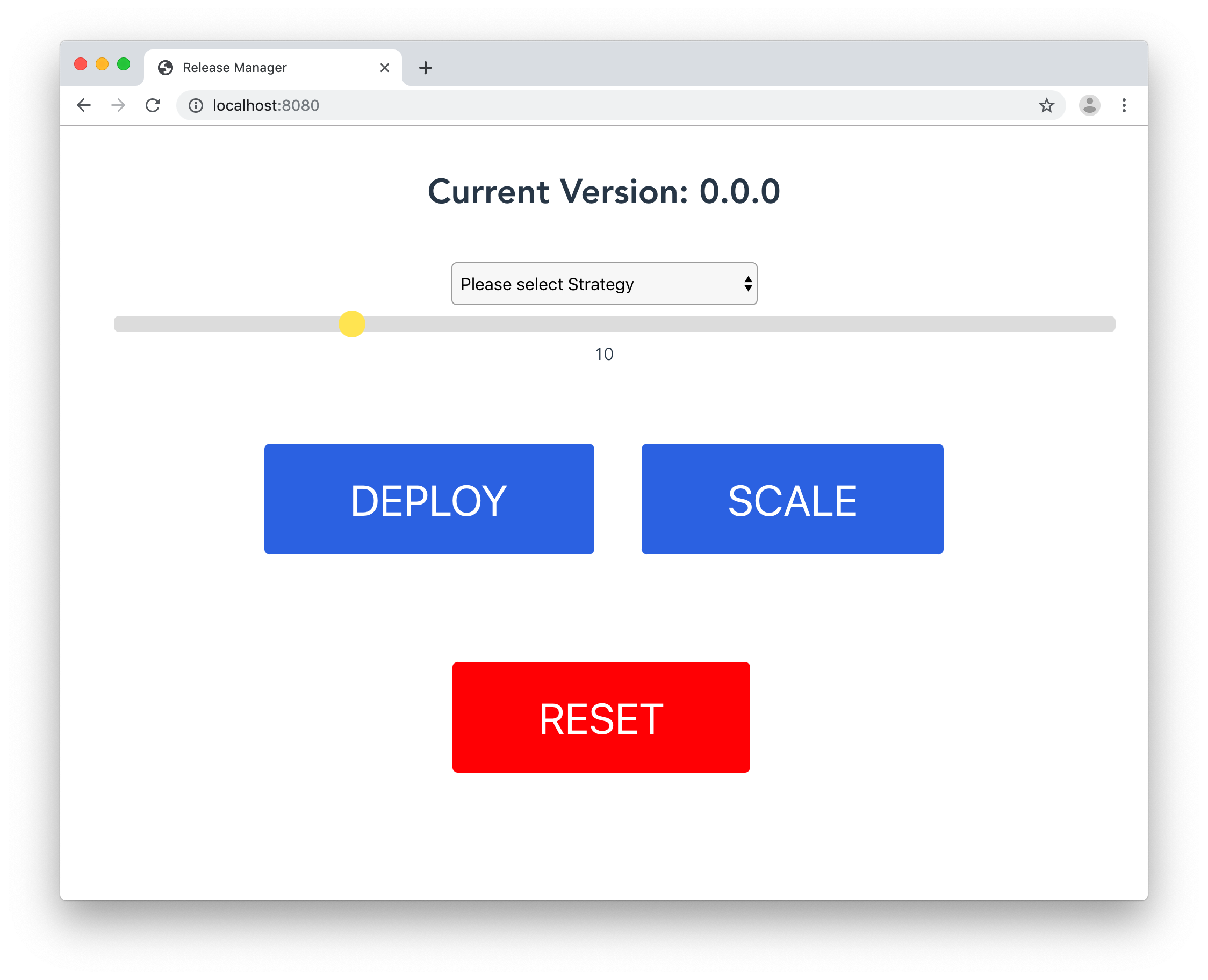
Um die neue Version sichtbar zu machen, bekommen Pods der neuen Version einfach ein neues Farblabel verpasst.
Damit gilt für alle folgenden Gifs: Gelb ist v1, Violett v2.
Unter der Haube werden dort lediglich Shell Skripte ausgeführt, um das Management unseres Beispiel-Deployments zu vereinfachen, setzen wir hier auf Helm.
Einerseits erleichtert uns Helm einige Deploymentschritte, andererseits verliert man etwas an Flexibilität, die bei einigen Strategien durchaus hilfreich wäre.
Scaling
Wir fangen erstmal langsam an und skalieren unsere Pods mit folgendem einfachen Befehl.
Über die Weboberfläche verschiebt man einfach den Slider und klickt Scale
helm upgrade whoami --reuse-values --set replicaCount=$1 ./whoami/ --wait
\


Recreate
Recreate ähnelt am ehesten einer klassichen Installation von Software: Die alte Version wird heruntergefahren und deinstalliert, danach wird die neue installiert.
Der dazugehörige Befehl sieht dann so aus:
helm upgrade whoami --reuse-values \
--set color=A81399 --set strategy=recreate \
--set version=2.2.0 \
./whoami/
\

Rolling
Rolling Upgrades sind der Standard Upgradeprozess für Kubernetes Deployments, demnach ist hier wenig an weiteren Argumenten zu übergeben.
\
Der Traffic wird nach und nach von der neuen Version übernommen, eine Veränderung des Services oder Ingress ist nicht nötig.
\
Mit "--reuse-values" werden lediglich die Werte des Deployments verändert, die im Befehl auch angegeben sind. Es wird als Basis also das bestehende Deployment gewählt und nicht, wie sonst üblich, die Manifestfiles.
Damit verstoßen wir zwar gegen unser Bestreben, möglichst viel deklarativ zu beschreiben, in dem Fall einer reinen Demo überwiegt aber der Vorteil, die Skripte möglichst einfach und kurz zu halten.
helm upgrade whoami --reuse-values --set color=A81399 --set version=2.2.0 ./whoami/ --wait
\

Blue-Green
Beim Blue-Green Deployment werden zunächst alle Pods der neuen Version hochgefahren und erst, wenn alle Pods bereit sind, wird der Traffic auf einen Schlag auf die neue Version geleitet.
Danach wird die alte version heruntergefahren.
Diese Strategie hat den Nachteil, dass kurzfristig die doppelten Resourcen zur Verfügung stehen müssen.
In unserem Skript geschiet dieses Upgrade wie folgt:
helm install --name whoamiv2 --set color=A81399 --set version=2.2.0 ./whoami/ --wait
# Alle Pods von v2 sind bereit. Ingress wird gepatcht...
kubectl patch ing/whoami-ingress --type=json \
-p='[{"op": "replace", "path": "/spec/rules/0/http/paths/0/backend/serviceName", "value":"whoamiv2"}]'
\

Canary
Ein Canary Deployment ist die anspruchsvollste, letztlich aber wohl auch die eleganteste und anstrebenswerteste Methode.
# Patch für Canary im Ingress
cat <<EOF >> canary.yaml
metadata:
annotations:
traefik.ingress.kubernetes.io/service-weights: |
whoami: 95%
whoamiv2: 5%
EOF
# Skript
helm install --name whoamiv2 --set color=A81399 --set version=2.2.0 \
--set replicaCount=2 \
./whoami/ --wait
# Ingress 90/10
kubectl patch ingress whoami-ingress --patch "$(cat ingress/canary.yaml)"
# Im produktiveinsatz sollte dieser Zeitraum natürlich länger sein, und
# Metriken und Logs der neuen Version geprüft werden, ob sie wirklich
# stabil läuft.
sleep 30
# Nach der zeit nehmen wir an, die neue Version funktioniert einwandfrei # und wir wollen nun auch den Rest upgraden.
echo "Scaling up v2"
helm upgrade whoamiv2 --reuse-values --set replicaCount=2 \
--set version=2.2.0 ./whoami/
# Ingress Patch für den Betrieb mit v2
cat <<EOF >> canary.yaml
metadata:
annotations:
traefik.ingress.kubernetes.io/service-weights: |
whoami: 0%
whoamiv2: 100%
EOF
echo "100% Traffic on v2"
kubectl patch ingress whoami-ingress --patch "$(cat ingress/canary-after.yaml)"
echo "delete v1"
helm del --purge whoami
\

Fazit
Kubernetes schafft als weitere Abstraktionsebene noch mehr Abstand zur eigentlichen Hardware. Manchmal braucht man aber ein Verständnis und Vorstellung der Grundlagen um eventuelle Proleme zu lösen.
Hier schlagen wir den Bogen zurück zu I/O und physischer Hardware um eben jener Vorstellung auf die Sprünge zu helfen.
Wenn du unser Cluster mal selbst in Aktion sehen willst, besuch uns auf einem der nächsten Kubernetes Trainings oder statte uns einen Besuch in unserem Office ab.
Wir freuen uns auf Dich!
die bee42 Crew